MySQL 一个查询语句的执行顺序
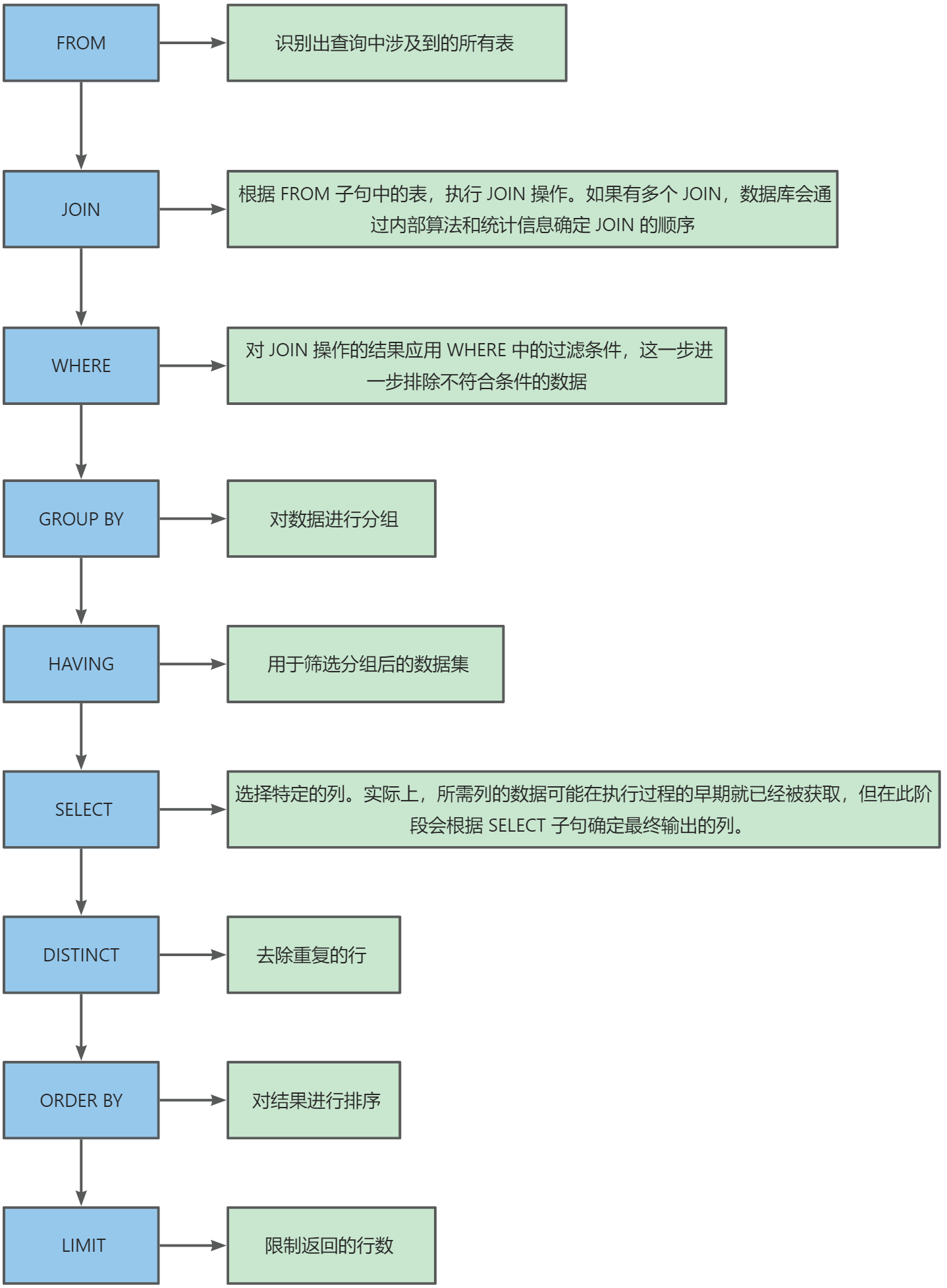
FROM:第一步肯定要先识别出查询中涉及的所有表。JOIN:根据FROM子句中的表,执行JOIN操作。如果有多个JOIN,数据库会根据内部算法和统计信息确定JOIN的顺序,以尝试优化查询效率。WHERE:对JOIN操作的结果应用WHERE中的过滤条件。这一步会排除不符合条件的行。GROUP BY:如果查询包含GROUP BY子句,此时对数据进行分组。分组操作通常在WHERE条件过滤之后进行。HAVING:如果有HAVING子句,它会在GROUP BY之后应用。HAVING子句用于筛选分组后的数据集。SELECT:选择特定的列。实际上,所需列的数据可能在执行过程的早期就已经被获取,但在此阶段会根据SELECT子句确定最终输出的列。DISTINCT:如果指定了DISTINCT关键字,此时会去除重复的行。ORDER BY:如果查询指定了ORDER BY,现在将对结果进行排序。注意,如果使用了GROUP BY,MySQL 可能会利用这个排序作为GROUP BY的一部分。LIMIT:最后,应用LIMIT子句来限制返回的行数。这通常是整个查询过程的最后一步。
举个例子:
SELECT name, COUNT(*)
FROM employees
JOIN departments ON employees.department_id = departments.id
WHERE employees.salary > 50000
GROUP BY departments.name
HAVING COUNT(*) > 10
ORDER BY name
LIMIT 5;如上面的SQL,我们是找出平均薪水超过 50,000 的部门中员工人数超过 10 人的前 5 个部门,他的执行过程如下:
FROM:确定涉及的表:employees和departments。JOIN:根据employees.department_id = departments.id条件执行JOIN操作,将两个表的数据合并。WHERE:应用WHERE过滤条件employees.salary > 50000,只保留薪水超过 50,000 的员工记录。GROUP BY:根据departments.name对结果集进行分组。HAVING:应用HAVING条件COUNT(*) > 10,筛选出员工人数超过 10 人的部门。SELECT:选择要显示的列:name(部门名称)和COUNT(*)(员工数量)。DISTINCT:此查询没有使用DISTINCT关键字,所以跳过。ORDER BY:根据name(部门名称)对结果集进行排序。LIMIT:应用LIMIT,只返回前 5 条记录。